大一的时候发现的一个比较有意思的网站:黑板课爬虫闯关,可以用来Python练手.当时我只做了前两关,第三关因为觉得登陆完跳转莫名奇妙的,就没再做下去.最近又看到了这个闯关题目于是抽空通关了一下.
先看下自己大一写的代码,真的惨不忍睹:
1 | from urllib import request |
第一关没啥好说的.就是不断的请求网页,拼接URL直到获得Flag就好了.
第二关加了账户和密码,也很简单,就是一个POST Method,怎么实现都行.
第三关,就是我当时放弃的那关.当时我发现登录后会跳转到黑板课记账的页面,不明所以,于是就没再做了,其实只要再按浏览器返回键就好了…
这一关加了CSRFTOKEN验证和登录操作.首先要登录黑板课网站,然后才能进行闯关.而闯关页面多两层保护的意思其实就是登录黑板课网站和闯关都需要CSRFTOKEN,CSRFTOKEN从cookies里取或者直接爬网页标签里的都可以.
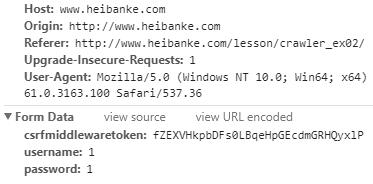
也就是说登录黑板课之前要获取CSRFTOKEN,然后与你的账户密码一块POST,闯关页面同理,也要先获取CSRF字段,注意两个CSRF字段值是不一样的.
第四关,在第三关的基础上又加了多线程.随便输一个账户密码进去,会提示你密码可以在一个链接里找,打开链接是密码位置与值对应的一个表,总共有13页.而这个网站载入又贼慢,就是想让你用多线程的方法去访问.注意访问不要太频繁,同时开的线程太多,网站会无法访问.
拼接好密码再加上用户名和csrftoken访问即可.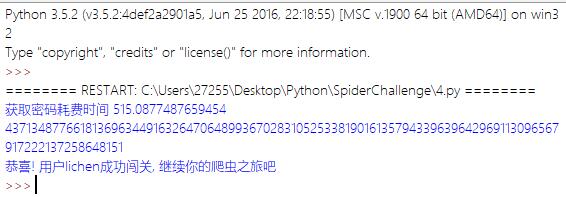
Bingo!整100位的密码,不过为啥我用了多线程还是花了这么长时间…
5.最后一关,在第三关的基础上加了验证码.我不会图像识别,于是直接暴力人工打码了,希望以后能有更优雅的实现. 所有代码:
因为很多时候只是为了得到运行结果,并且都是半夜写的!代码写的并不是很Pythonic.以后还是尽量要把代码写的简洁优雅,追求可读性高的写法.最起码以后看的时候不会那么难受,这也算是一个小小的目标吧.